1. Research Gap
Most of the KG embedding algorithms focus on multi-realational graphs composed of triples in RDF; Geometric learning is limited to a fragment of OWL; OPA2Vec fails to utilize the semantic relationships between axioms.
2. Preliminaries
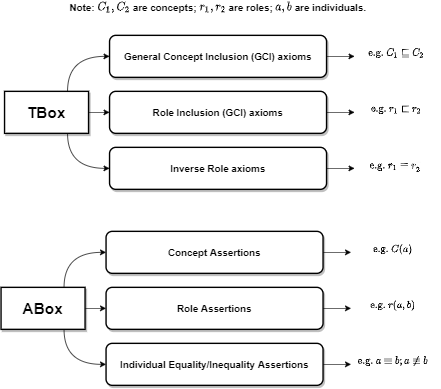
- OWL Ontologies: (1) An OWL ontology comprises a TBox \(\mathcal{T}\) and an ABox \(\mathcal{A}\); (2) In OWL, concepts, roles and individuals are referred as
classes,object propertiesandinstances; (3) A KG can often be understood as an ontology.
- Semantic Embedding: (1) An end-to-end paradigm for learning KG embeddings is by iteratively adjusting the vectors using an optimization algorithm to minimize the loss usually calculated by scoring the truth/falsity of each triple (positive and negative samples), e.g. TransE, TransR and DistMult; (2) Another paradigm is to first explicitly explore the neighborhoods, and then learn embeddings using a
language modelcorpus built from the graph. The work of OWL2Vec* is this paper belongs to paradigm (2).
3. Methodology
The framework of OWL2Vec* consits of two core steps: (i) corpus extraction and (ii) language modelling word representation learning (see figure below).
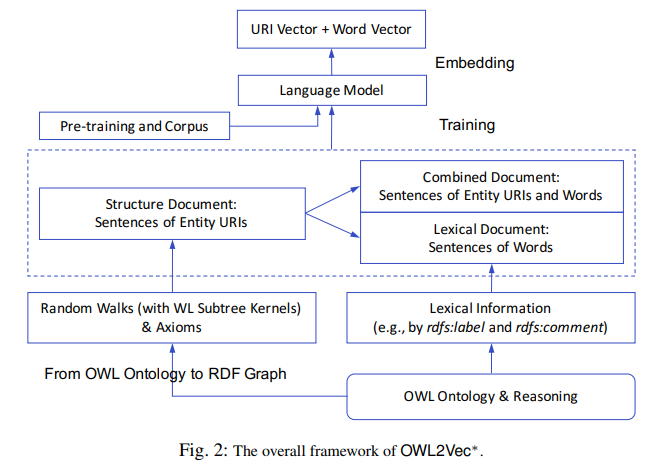
The overall procedure can be understood from bottom up:
-
There are two strategies for converting OWL ontologies to RDF graphs: (i) Graph Mapping (W3C) and (ii) Projection Rules (approx.), both of which can be accompanied by an OWL reasoner (HermiT reasoner in this paper).
-
Structure Document is generated by computing random walks for each target entity with a RDF graph. Each walk is a sequence of entity URIs. Another option is to use Weisfeiler Lehman (WL) RDF. The WL subtree kernel solution replaces the final entity of each random walk with the kernel (identity) of the sub-tree rooted in this entity.
Note: OWL2Vec* also extracts all the axioms (transformed by OWL Manchester Syntax) of the ontology as a complement.
- Lexical Document consists of (i) word sentences transformed from the entity URI sentences in the Structure Document and (ii) relevant lexical annotation axioms in the ontology. Each entity URI is replaced by its English label defined by
rdfs:label(characters are lowercased and none letter characters are removed). If no (English) annotations, use the name part of the entity URI (e.g.beerinvc:Beer,typeinrdf:type).
Note: (ii) is the one of the highlights in this paper as it considers bespoke annotation properties in the ontology such as “definition”. Also, axioms by
rdf:labelare ignored as they are already used in replacing entity URIs.
- Combined Document is formed by leaving one entity URI unchanged in each sentence so as to preserve the correlation between URIs and words.
The ultimate corpus is formed by merging all the three documents mentioned above together, then use it to train word representations with a chosen embedding architecture (Word2Vec in this paper). Prior correlations can be introduced by adding pre-trained language model word embeddings but they may be noisy in a domain specific task.
The output vectors for an entity \(e\) is \(V_{URI}(e)\) (vector for the URI) and \(V_{word}(e)\) (vector for averaging the vectors of all the word tokens of \(e\), i.e. English label or URI name).
4. Downstream Tasks
-
(A) Class Membership Prediction: Train a model to predict the plausibility that \(e_1\) (instance) is a member of \(e_2\) (class), i.e. \(e_2(e_2)\). The input is \(\mathbf{x} = [\mathbf{e_1}, \mathbf{e_2}]\) and the output is a score \(y \in [0, 1]\). Prediction is made by binary machine learning classifier such as Random Forest. In training, for each positive sample \((e_1, e_2)\) with \(e_2(e_1)\), generate a negative sample \((e_1, e_2')\) such that \(\not e_2'(e_1)\) after entailment reasoning.
-
(B) Class Subsumption Prediction (\(e_1 \sqsubseteq e_2\)) is a similar task except that both \(e_1\) and \(e_2\) are classes.
5. Evaluation
- Data & Code in https://github.com/KRR-Oxford/OWL2Vec-Star.
- Datasets: HeLis for task (A), FoodOn and GO for task (B). All partitioned into \(7:1:2\) (\(tra:val:tst\)).
- Both tasks take a head entity, predict its class and compare it against the tail entity in the evaluation.
- All the candidates are ranked according to predicted score, and metrics adopted are Hits@1, Hits@5, Hits@10 and MRR (Mean Reciprocal Rank).
- Hits@\(n\) measures the recall of the ground truths within the top \(n\) ranking positions, i.e. at position \(n\), how many correct classes are predicted for the head entity.
- MRR averages the reciprocals of the ranking positions of the ground truths.
- Comparison against the traditional, the state-of-the-art and the previous OWL2Vec embedding models suggests that OWL2Vec* outperforms all of them, and it achieves great result (\(> 90\%\)) on HeLis dataset. The author argued that lexical information is vital for embedding real-world ontologies because even the pre-trained Word2Vec model outperforms those with only URI embeddings. The performance on FoodOn and GO is less promising and the author suggested that it results from the number of candidate classes (\(277\) vs. \(28,182\) vs. \(44,244\)).
6. Ablation Study
[Lexical Information]:
- The lexical document leads to significant improvement when it is merged with the structure document.
- Combined document leads to a limited positive impact. It benefits when only URI embeddings are used but it introduces nosie to the correlation between words when word embeddings are used.
- URI embeddings show positive impact on (A) but negative on (B).
[Graph Structure]:
-
RDF Graph Mapping (W3C) keeps all the semantics but leads to redundancy; Projection rules gives more compact graph but approximate most axioms with logical constructors (semantic loss). The former is chosen unlike the original OWL2Vec where the latter is chosen.
-
WL Subtree Kernel performs better than Random Walk in the ablation settings.
[Logical Constructors]:
- Logical structure alone gives relatively poor performance, but a positive impact when it works together with the graph structure; OWL2Vec* uses axiom sentences while RDF2Vec does not; Impact of Reasoner is limited.
[Pre-trained Corpus]:
- Pre-trained Word2Vec does not help because the ontology is domain-specific.
7. Conclusion
OWL2Vec* extracts documents from the ontology that capture its graph structure, axioms of logical constructors, as well as its lexical information, and then learns a neural language model representation learning model for both entity URI and word embeddings. Future work includes incorporating new feature learning model architectures and better generalization.
References
- Chen, Jiaoyan, Pan Hu, Ernesto Jiménez-Ruiz, Ole Magnus Holter, Denvar Antonyrajah and I. Horrocks. “OWL2Vec*: Embedding of OWL Ontologies.” ArXiv abs/2009.14654 (2020): n. pag.