2025
Supposedly Equivalent Facts That Aren’t? Entity Frequency in Pre-training Induces Asymmetry in LLMs
Yuan He*, Bailan He*, Zifeng Ding*, Alisia Maria Lupidi, Yuqicheng Zhu, Shuo Chen, Caiqi Zhang, Jiaoyan Chen, Yunpu Ma, Volker Tresp, Ian Horrocks
COLM 2025
TL;DR: This work demonstrates that the asymmetry in how large language models recognise equivalent facts stems from inherent biases in their pre-training data, particularly through differences in entity frequency.
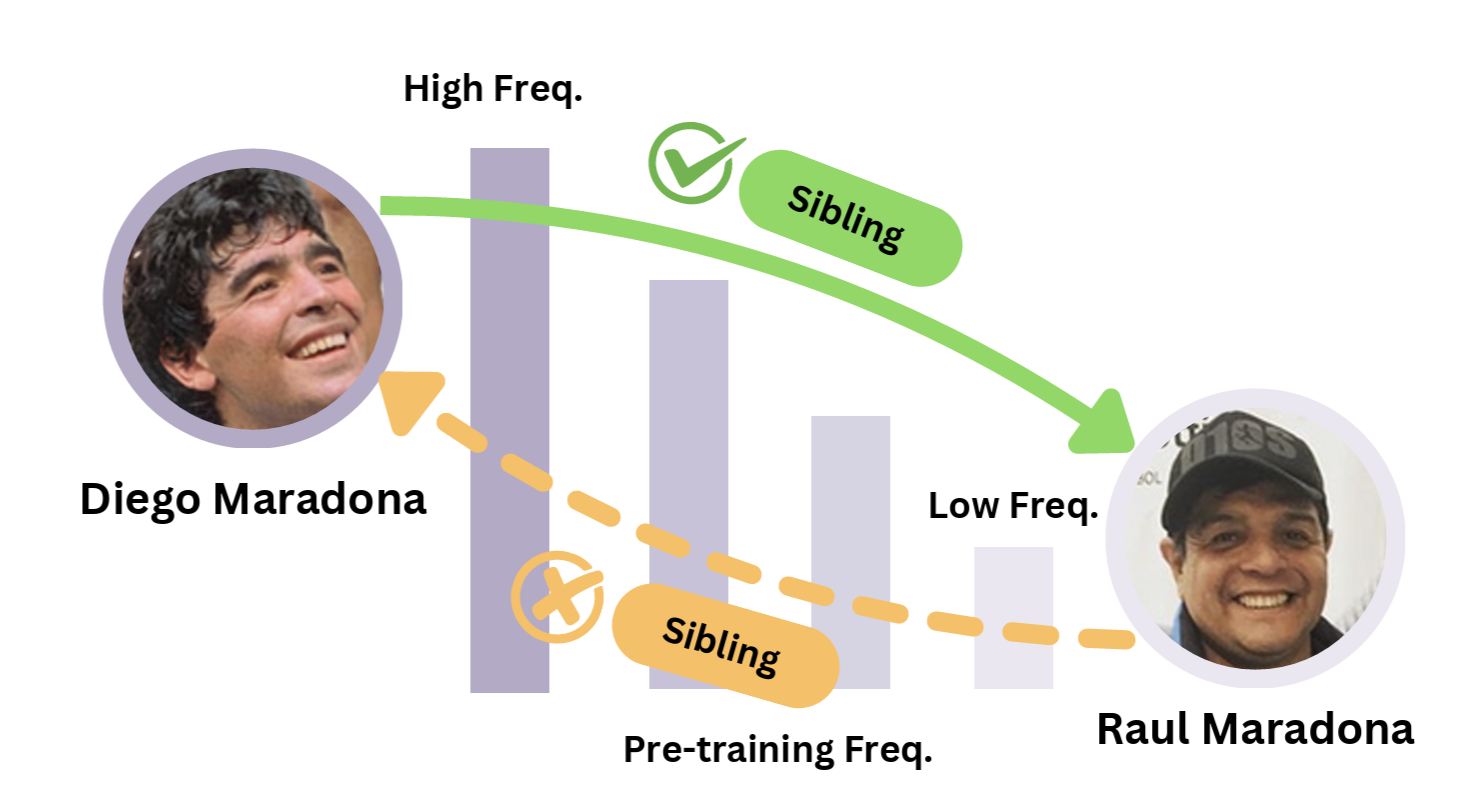
Abstract: Understanding and mitigating hallucinations in Large Language Models (LLMs) is crucial for ensuring reliable content generation. While previous research has primarily focused on "when" LLMs hallucinate, our work explains "why" and directly links model behaviour to the pre-training data that forms their prior knowledge. Specifically, we demonstrate that an asymmetry exists in the recognition of logically equivalent facts, which can be attributed to frequency discrepancies of entities appearing as subjects versus objects. Given that most pre-training datasets are inaccessible, we leverage the fully open-source OLMo series by indexing its Dolma dataset to estimate entity frequencies. Using relational facts (represented as triples) from Wikidata5M, we construct probing datasets to isolate this effect. Our experiments reveal that facts with a high-frequency subject and a low-frequency object are better recognised than their inverse, despite their logical equivalence. The pattern reverses in low-to-high frequency settings, and no statistically significant asymmetry emerges when both entities are high-frequency. These findings highlight the influential role of pre-training data in shaping model predictions and provide insights for inferring the characteristics of pre-training data in closed or partially closed LLMs.
Distilling Tool Knowledge into Language Models via Back-Translated Traces
Xingyue Huang, Xianglong Hu, Zifeng Ding, Yuan He, Rishabh, Waleed Alzarooni, Ziyu Ye, Wendong Fan, Bailan He, Haige Bo, Changran Hu, Guohao Li
MAS@ICML 2025
TL;DR: We introduce a tool-integrated reasoning pipeline for LLMs to learn mathematical reasoning.
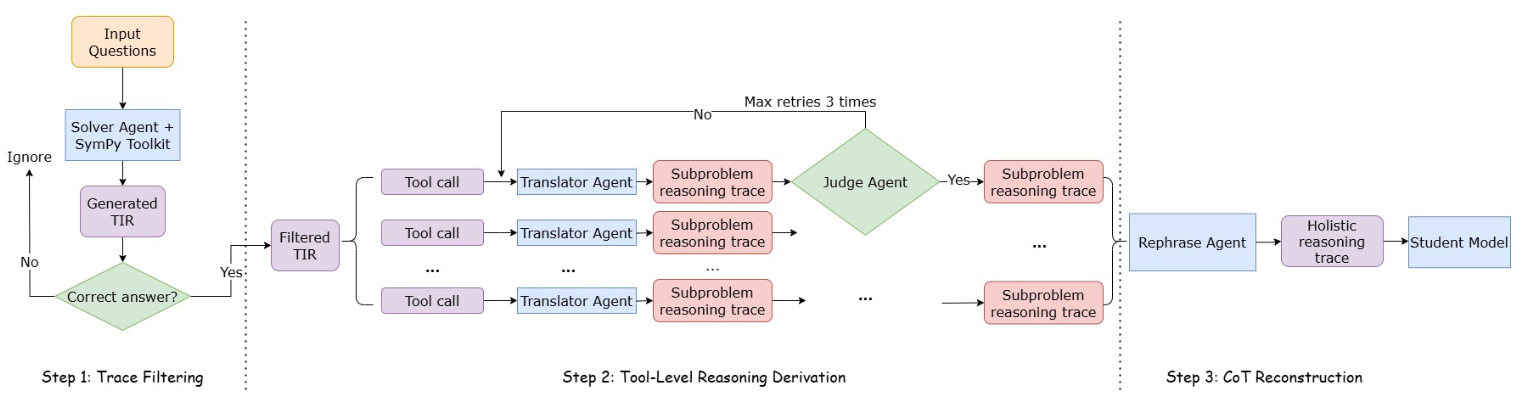
Abstract: Large language models (LLMs) often struggle with mathematical problems that require exact computation or multi-step algebraic reasoning. Tool-integrated reasoning (TIR) offers a promising solution by leveraging external tools such as code interpreters to ensure correctness, but it introduces inference-time dependencies that hinder scalability and deployment. In this work, we propose a new paradigm for distilling tool knowledge into LLMs purely through natural language. We first construct a Solver Agent that solves math problems by interleaving planning, symbolic tool calls, and reflective reasoning. Then, using a back-translation pipeline powered by multiple LLM-based agents, we convert interleaved TIR traces into natural language reasoning traces. A Translator Agent generates explanations for individual tool calls, while a Rephrase Agent merges them into a fluent and globally coherent narrative. Empirically, we show that fine-tuning a small open-source model on these synthesized traces enables it to internalize both tool knowledge and structured reasoning patterns, yielding gains on competition-level math benchmarks without requiring tool access at inference.
Predicate-Conditional Conformalized Answer Sets for Knowledge Graph Embeddings
Yuqicheng Zhu, Daniel Hernández, Yuan He, Zifeng Ding, Bo Xiong, Evgeny Kharlamov, Steffen Staab
ACL Findings 2025
TL;DR: Uncertainty quantification in Knowledge Graph Embedding.
Abstract: Uncertainty quantification in Knowledge Graph Embedding (KGE) methods is crucial for ensuring the reliability of downstream applications. A recent work applies conformal prediction to KGE methods, providing uncertainty estimates by generating a set of answers that is guaranteed to include the true answer with a predefined confidence level. However, existing methods provide probabilistic guarantees averaged over a reference set of queries and answers (marginal coverage guarantee). In high-stakes applications such as medical diagnosis, a stronger guarantee is often required: the predicted sets must provide consistent coverage per query (conditional coverage guarantee). We propose CondKGCP, a novel method that approximates predicate-conditional coverage guarantees while maintaining compact prediction sets. CondKGCP merges predicates with similar vector representations and augments calibration with rank information. We prove the theoretical guarantees and demonstrate empirical effectiveness of CondKGCP by comprehensive evaluations.
DyGMamba: Efficiently Modeling Long-Term Temporal Dependency on Continuous-Time Dynamic Graphs with State Space Models
Zifeng Ding, Yifeng Li, Yuan He, Antonio Norelli, Jingcheng Wu, Volker Tresp, Yunpu Ma, Michael Bronstein.
TMLR 2025
TL;DR: We introduce DyGMamba, a model that utilizes state space models (SSMs) for continuous-time dynamic graph (CTDG) representation learning.
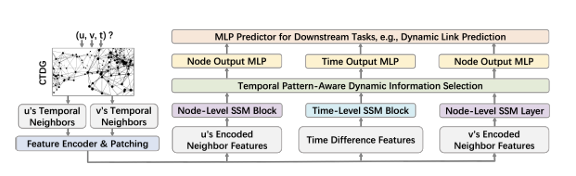
Abstract: Learning useful representations for continuous-time dynamic graphs (CTDGs) is challenging, due to the concurrent need to span long node interaction histories and grasp nuanced temporal details. In particular, two problems emerge: (1) Encoding longer histories requires more computational resources, making it crucial for CTDG models to maintain low computational complexity to ensure efficiency; (2) Meanwhile, more powerful models are needed to identify and select the most critical temporal information within the extended context provided by longer histories. To address these problems, we propose a CTDG representation learning model named DyGMamba, originating from the popular Mamba state space model (SSM). DyGMamba first leverages a node-level SSM to encode the sequence of historical node interactions. Another time-level SSM is then employed to exploit the temporal patterns hidden in the historical graph, where its output is used to dynamically select the critical information from the interaction history. We validate DyGMamba experimentally on the dynamic link prediction task. The results show that our model achieves state-of-the-art in most cases. DyGMamba also maintains high efficiency in terms of computational resources, making it possible to capture long temporal dependencies with a limited computation budget.
Ontology Embedding: A Survey of Methods, Applications and Resources
Jiaoyan Chen, Olga Mashkova, Fernando Zhapa-Camacho, Robert Hoehndorf, Yuan He, Ian Horrocks
IEEE Transactions on Knowledge and Data Engineering 2025
TL;DR: A comprehensive survey of ontology embeddings.
Abstract: Ontologies are widely used for representing domain knowledge and meta data, playing an increasingly important role in Information Systems, the Semantic Web, Bioinformatics and many other domains. However, logical reasoning that ontologies can directly support are quite limited in learning, approximation and prediction. One straightforward solution is to integrate statistical analysis and machine learning. To this end, automatically learning vector representation for knowledge of an ontology i.e., ontology embedding has been widely investigated in recent years. Numerous papers have been published on ontology embedding, but a lack of systematic reviews hinders researchers from gaining a comprehensive understanding of this field. To bridge this gap, we write this survey paper, which first introduces different kinds of semantics of ontologies, and formally defines ontology embedding from the perspectives of both mathematics and machine learning, as well as its property of faithfulness. Based on this, it systematically categorises and analyses a relatively complete set of over 80 papers, according to the ontologies and semantics that they aim at, and their technical solutions including geometric modeling, sequence modeling and graph propagation. This survey also introduces the applications of ontology embedding in ontology engineering, machine learning augmentation and life sciences, presents a new library mOWL, and discusses the challenges and future directions.
Evaluating Knowledge Graph Based Retrieval Augmented Generation Methods under Knowledge Incompleteness
Dongzhuoran Zhou, Yuqicheng Zhu, Yuan He, Jiaoyan Chen, Evgeny Kharlamov, Steffen Staab
Arxiv 2025
TL;DR: Evaluating KG-based RAG on KG incompleteness
Abstract: Knowledge Graph based Retrieval-Augmented Generation (KG-RAG) is a technique that enhances Large Language Model (LLM) inference in tasks like Question Answering (QA) by retrieving relevant information from knowledge graphs (KGs). However, real-world KGs are often incomplete, meaning that essential information for answering questions may be missing. Existing benchmarks do not adequately capture the impact of KG incompleteness on KG-RAG performance. In this paper, we systematically evaluate KG-RAG methods under incomplete KGs by removing triples using different methods and analyzing the resulting effects. We demonstrate that KG-RAG methods are sensitive to KG incompleteness, highlighting the need for more robust approaches in realistic settings.
2024
Results of the Ontology Alignment Evaluation Initiative 2024
OAEI Organisers
OM@ISWC 2024
TL;DR: A joint report for results of different OAEI tracks in 2024.
Abstract:
Language Models as Hierarchy Encoders
Yuan He, Zhangdie Yuan, Jiaoyan Chen, Ian Horrocks
NeurIPS 2024
TL;DR: We introduce a novel approach to re-train transformer encoder-based language models as Hierarchy Transformer encoders (HiTs), leveraging the expansive nature of hyperbolic psace.
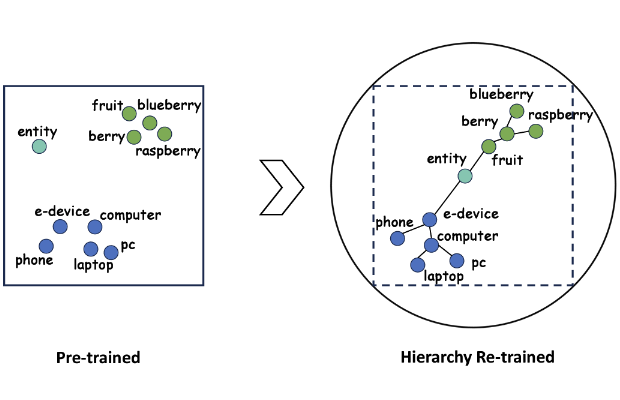
Abstract: Interpreting hierarchical structures latent in language is a key limitation of current language models (LMs). While previous research has implicitly leveraged these hierarchies to enhance LMs, approaches for their explicit encoding are yet to be explored. To address this, we introduce a novel approach to re-train transformer encoder-based LMs as Hierarchy Transformer encoders (HiTs), harnessing the expansive nature of hyperbolic space. Our method situates the output embedding space of pre-trained LMs within a Poincaré ball with a curvature that adapts to the embedding dimension, followed by training on hyperbolic clustering and centripetal losses. These losses are designed to effectively cluster related entities (input as texts) and organise them hierarchically. We evaluate HiTs against pre-trained LMs, standard fine-tuned LMs, and several hyperbolic embedding baselines, focusing on their capabilities in simulating transitive inference, predicting subsumptions, and transferring knowledge across hierarchies. The results demonstrate that HiTs consistently outperform all baselines in these tasks, underscoring the effectiveness and transferability of our re-trained hierarchy encoders.
Language Models for Ontology Engineering
Yuan He
University of Oxford (PhD Thesis) 2024
TL;DR: My PhD Thesis.
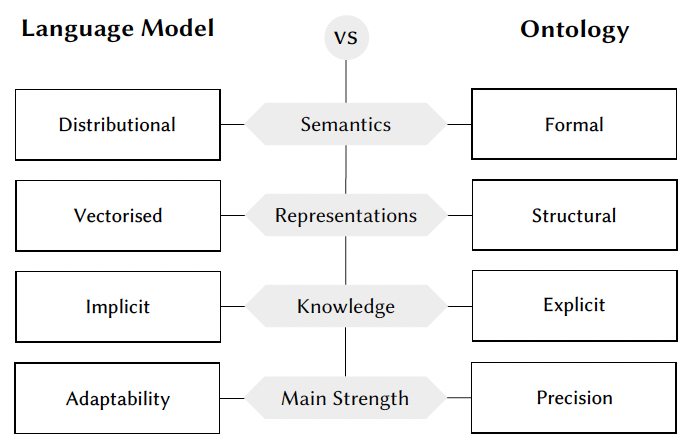
Abstract: Ontology, originally a philosophical term, refers to the study of being and existence. The concept was introduced to Artificial Intelligence (AI) as a knowledge-based system that can model and share knowledge about entities and their relationships in a machine-readable format. Ontologies offer a structured and logical formalism of human knowledge, enabling expressive representations and reliable reasoning within defined domains. Meanwhile, modern deep learning-based language models (LMs) represent a significant milestone in the field of Natural Language Processing (NLP), as they incorporate substantial background knowledge from the vast and complex distribution of textual data. This thesis explores the synergy between these two paradigms, focusing primarily on the use of LMs in ontology engineering and, more broadly, in knowledge engineering. The goal is to automate or semi-automate the process of ontology construction and curation. Ontology engineering includes a wide array of tasks within the life cycle of ontology development. This thesis concentrates on three key aspects: (i) ontology alignment, which seeks to align equivalent concepts across different ontologies to achieve data integration; (ii) ontology completion, which focuses on filling in missing subsumption relationships between ontology concepts; and (iii) hierarchy embedding, which aims to develop versatile and interpretable neural representations for hierarchical structures derived not only from ontologies but also applicable to other forms of hierarchical data. These representations can facilitate a broad spectrum of downstream ontology engineering tasks, such as (i) and (ii), and are adaptable for more general applications in hierarchy-aware contexts. This thesis is organised into three parts. The first part establishes the foundations necessary for understanding ontologies and LMs. The chapter on ontologies initiates with a basic overview of computational ontologies, then provides an introduction of the description logic formalisms that underpin them. It concludes with the formal definitions of the three ontology engineering tasks this thesis focuses on. Transitioning to LMs, the subsequent chapter begins with a chronological overview of their evolution, followed by detailed exposition of various typical LMs along this evolution. The discussion then proceeds to contemporary transformer-based LMs, elaborating on their architecture and different learning paradigms they adopt. The chapter concludes with a review of how LMs and knowledge bases (including ontologies) interact and influence each other, highlighting the mutual benefits of this integration for both fields of study. With the comprehensive background provided in the first part, the second part of the thesis delves into specific methodologies that have been developed. This part comprises three chapters, each corresponding to the application of LMs in ontology alignment, ontology completion, and hierarchy embedding, respectively. In the chapter on LMs for ontology alignment, we introduce BERTMap, a novel pipeline system that employs LM fine-tuning for improved alignment prediction and ontology semantics for alignment refinement. We will also mention the Bio-ML track of the Ontology Alignment Evaluation Initiative (OAEI), which has emerged as a benchmarking platform for a variety of ontology alignment systems over the past two years. The chapter on LMs for ontology completion presents OntoLAMA, a collection of LM probing datasets and a prompt-based LM probing approach that effectively predicts subsumptions, even with limited training resources. Lastly, the section on LMs for hierarchy embedding discusses the re-training of LMs as Hierarchy Transformer encoders (HiT), addressing the limitations of LMs in explicitly interpreting and encoding hierarchies, including those extracted from ontologies. The third part of the thesis details the practical implementations. We mainly present DeepOnto, a Python package designed for ontology engineering utilising deep learning, with an emphasis on LMs. DeepOnto offers a range of basic to advanced ontology processing functionalities to support deep learning-based ontology engineering development. This package also includes polished implementations of our systems and resources mentioned in Part II. In summary, this thesis advocates for a more holistic approach in AI development, where the integration of LMs and ontologies can lead to a more advanced, explainable, and useful paradigm in knowledge engineering and beyond.
DeepOnto: A Package for Ontology Engineering with Deep Learning
Yuan He, Jiaoyan Chen, Hang Dong, Ian Horrocks, Carlo Allocca, Taehun Kim, Brahmananda Sapkota
Semantic Web 2024
TL;DR: A Python package for ontology engineering with deep learning and language models.
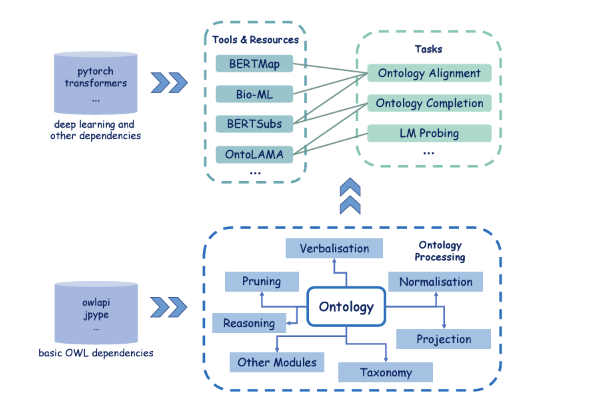
Abstract: Integrating deep learning techniques, particularly language models (LMs), with knowledge representation techniques like ontologies has raised widespread attention, urging the need of a platform that supports both paradigms. Although packages such as OWL API and Jena offer robust support for basic ontology processing features, they lack the capability to transform various types of information within ontologies into formats suitable for downstream deep learning-based applications. Moreover, widely-used ontology APIs are primarily Java-based while deep learning frameworks like PyTorch and Tensorflow are mainly for Python programming. To address the needs, we present DeepOnto, a Python package designed for ontology engineering with deep learning. The package encompasses a core ontology processing module founded on the widely-recognised and reliable OWL API, encapsulating its fundamental features in a more "Pythonic" manner and extending its capabilities to incorporate other essential components including reasoning, verbalisation, normalisation, taxonomy, projection, and more. Building on this module, DeepOnto offers a suite of tools, resources, and algorithms that support various ontology engineering tasks, such as ontology alignment and completion, by harnessing deep learning methods, primarily pre-trained LMs. In this paper, we also demonstrate the practical utility of DeepOnto through two use-cases: the Digital Health Coaching in Samsung Research UK and the Bio-ML track of the Ontology Alignment Evaluation Initiative (OAEI).
A Language Model based Framework for New Concept Placement in Ontologies
Hang Dong, Jiaoyan Chen, Yuan He, Yongsheng Gao, Ian Horrocks
ESWC 2024
TL;DR: Re-trieve and Re-rank pipeline (with LLMs) for ontology concept placement.
Abstract: We investigate the task of inserting new concepts extracted from texts into an ontology using language models. We explore an approach with three steps: edge search which is to find a set of candidate locations to insert (i.e., subsumptions between concepts), edge formation and enrichment which leverages the ontological structure to produce and enhance the edge candidates, and edge selection which eventually locates the edge to be placed into. In all steps, we propose to leverage neural methods, where we apply embedding-based methods and contrastive learning with Pre-trained Language Models (PLMs) such as BERT for edge search, and adapt a BERT fine-tuning-based multi-label Edge-Cross-encoder, and Large Language Models (LLMs) such as GPT series, FLAN-T5, and Llama 2, for edge selection. We evaluate the methods on recent datasets created using the SNOMED CT ontology and the MedMentions entity linking benchmark. The best settings in our framework use fine-tuned PLM for search and a multi-label Cross-encoder for selection. Zero-shot prompting of LLMs is still not adequate for the task, and we propose explainable instruction tuning of LLMs for improved performance. Our study shows the advantages of PLMs and highlights the encouraging performance of LLMs that motivates future studies.
Ground settlement prediction for open caisson shafts in sand using a neural network constrained by empiricism
Geyang Song, Yuan He, Brian Sheil, James Morris
Computers and Geotechnics 2024
TL;DR: Physics-informed neural network for ground settlement prediction.
Abstract:
2023
Results of the Ontology Alignment Evaluation Initiative 2023
OAEI Organisers
OM@ISWC 2023
TL;DR: A joint report for results of different OAEI tracks in 2023.
Abstract:
Exploring Large Language Models for Ontology Alignment
Yuan He, Jiaoyan Chen, Hang Dong, Ian Horrocks
ISWC (Posters & Demos) 2023
TL;DR: An exploration of LLMs' application in ontology alignment.
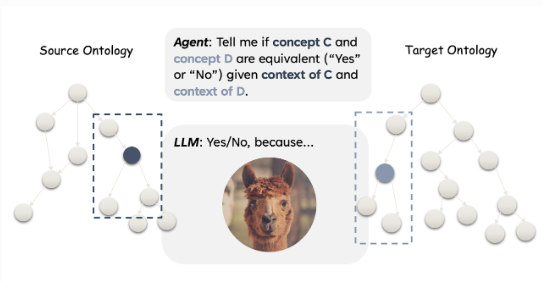
Abstract: This work investigates the applicability of recent generative Large Language Models (LLMs), such as the GPT series and Flan-T5, to ontology alignment for identifying concept equivalence mappings across ontologies. To test the zero-shot performance of Flan-T5-XXL and GPT-3.5-turbo, we leverage challenging subsets from two equivalence matching datasets of the OAEI Bio-ML track, taking into account concept labels and structural contexts. Preliminary findings suggest that LLMs have the potential to outperform existing ontology alignment systems like BERTMap, given careful framework and prompt design.
Ontology Enrichment from Texts: A Biomedical Dataset for Concept Discovery and Placement
Hang Dong, Jiaoyan Chen, Yuan He, Ian Horrocks
CIKM 2023 Best Resource Paper Runner-Up
TL;DR: A dataset for biomedical ontology concept discovery and placement.
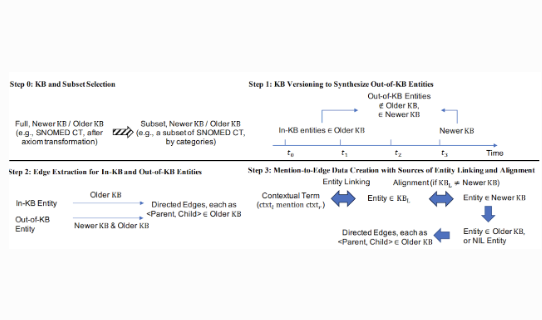
Abstract: Mentions of new concepts appear regularly in texts and require automated approaches to harvest and place them into Knowledge Bases (KB), e.g., ontologies and taxonomies. Existing datasets suffer from three issues, (i) mostly assuming that a new concept is pre-discovered and cannot support out-of-KB mention discovery; (ii) only using the concept label as the input along with the KB and thus lacking the contexts of a concept label; and (iii) mostly focusing on concept placement w.r.t a taxonomy of atomic concepts, instead of complex concepts, i.e., with logical operators. To address these issues, we propose a new benchmark, adapting MedMentions dataset (PubMed abstracts) with SNOMED CT versions in 2014 and 2017 under the Diseases sub-category and the broader categories of Clinical finding, Procedure, and Pharmaceutical / biologic product. We provide usage on the evaluation with the dataset for out-of-KB mention discovery and concept placement, adapting recent Large Language Model based methods.
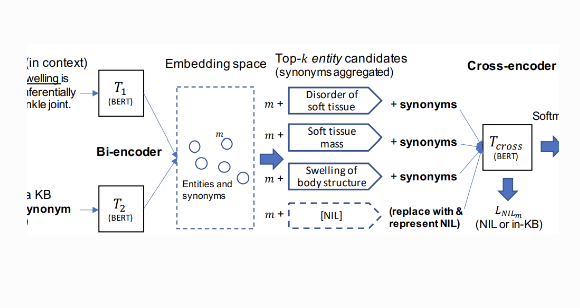
Reveal the Unknown: Out-of-Knowledge-Base Mention Discovery with Entity Linking
Hang Dong, Jiaoyan Chen, Yuan He, Yinan Liu, Ian Horrocks
CIKM 2023
TL;DR: We introduce BLINKout, an extension of the BLINK entity linking system to detect out-of-KB entities.
Abstract: Discovering entity mentions that are out of a Knowledge Base (KB) from texts plays a critical role in KB maintenance, but has not yet been fully explored. The current methods are mostly limited to the simple threshold-based approach and feature-based classification, and the datasets for evaluation are relatively rare. We propose BLINKout, a new BERT-based Entity Linking (EL) method which can identify mentions that do not have corresponding KB entities by matching them to a special NIL entity. To better utilize BERT, we propose new techniques including NIL entity representation and classification, with synonym enhancement. We also apply KB Pruning and Versioning strategies to automatically construct out-of-KB datasets from common in-KB EL datasets. Results on five datasets of clinical notes, biomedical publications, and Wikipedia articles in various domains show the advantages of BLINKout over existing methods to identify out-of-KB mentions for the medical ontologies, UMLS, SNOMED CT, and the general KB, WikiData.
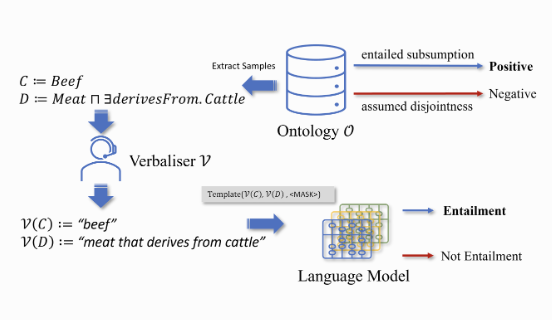
Language Model Analysis for Ontology Subsumption Inference
Yuan He, Jiaoyan Chen, Ernesto Jiménez-Ruiz, Hang Dong, Ian Horrocks
ACL (Findings) 2023
TL;DR: Probing the conceptual (ontological) knowledge in pre-trained language models.
Abstract: Investigating whether pre-trained language models (LMs) can function as knowledge bases (KBs) has raised wide research interests recently. However, existing works focus on simple, triple-based, relational KBs, but omit more sophisticated, logic-based, conceptualised KBs such as OWL ontologies. To investigate an LM's knowledge of ontologies, we propose OntoLAMA, a set of inference-based probing tasks and datasets from ontology subsumption axioms involving both atomic and complex concepts. We conduct extensive experiments on ontologies of different domains and scales, and our results demonstrate that LMs encode relatively less background knowledge of Subsumption Inference (SI) than traditional Natural Language Inference (NLI) but can improve on SI significantly when a small number of samples are given. We will open-source our code and datasets.
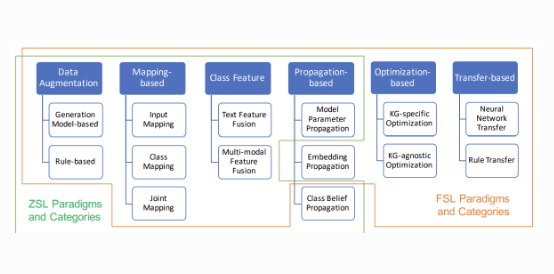
Zero-Shot and Few-Shot Learning With Knowledge Graphs: A Comprehensive Survey
Jiaoyan Chen, Yuxia Geng, Zhuo Chen, Jeff Z. Pan, Yuan He, Wen Zhang, Ian Horrocks, Huajun Chen
Proceedings of IEEE 2023
TL;DR: A comprehensive survey of zero-shot and few-shot learning with knowledge graphs.
Abstract: Machine learning (ML), especially deep neural networks, has achieved great success, but many of them often rely on a number of labeled samples for supervision. As sufficient labeled training data are not always ready due to, e.g., continuously emerging prediction targets and costly sample annotation in real-world applications, ML with sample shortage is now being widely investigated. Among all these studies, many prefer to utilize auxiliary information including those in the form of knowledge graph (KG) to reduce the reliance on labeled samples. In this survey, we have comprehensively reviewed over 90 articles about KG-aware research for two major sample shortage settings—zero-shot learning (ZSL) where some classes to be predicted have no labeled samples and few-shot learning (FSL) where some classes to be predicted have only a small number of labeled samples that are available. We first introduce KGs used in ZSL and FSL as well as their construction methods and then systematically categorize and summarize KG-aware ZSL and FSL methods, dividing them into different paradigms, such as the mapping-based, the data augmentation, the propagation-based, and the optimization-based. We next present different applications, including not only KG augmented prediction tasks such as image classification, question answering, text classification, and knowledge extraction but also KG completion tasks and some typical evaluation resources for each task. We eventually discuss some challenges and open problems from different perspectives.
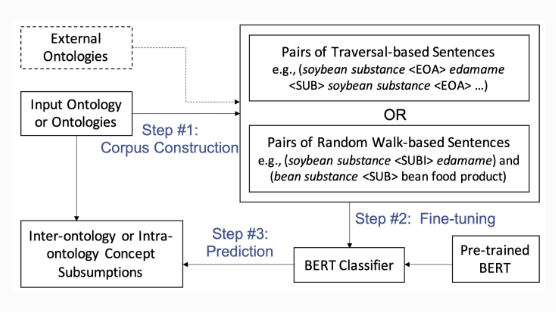
Contextual Semantic Embeddings for Ontology Subsumption Prediction
Jiaoyan Chen, Yuan He, Ernesto Jiménez-Ruiz, Hang Dong, Ian Horrocks
World Wide Web 2023
TL;DR: Fine-tuning BERT for ontology subsumption prediction.
Abstract: Automating ontology construction and curation is an important but challenging task in knowledge engineering and artificial intelligence. Prediction by machine learning techniques such as contextual semantic embedding is a promising direction, but the relevant research is still preliminary especially for expressive ontologies in Web Ontology Language (OWL). In this paper, we present a new subsumption prediction method named BERTSubs for classes of OWL ontology. It exploits the pre-trained language model BERT to compute contextual embeddings of a class, where customized templates are proposed to incorporate the class context (e.g., neighbouring classes) and the logical existential restriction. BERTSubs is able to predict multiple kinds of subsumers including named classes from the same ontology or another ontology, and existential restrictions from the same ontology. Extensive evaluation on five real-world ontologies for three different subsumption tasks has shown the effectiveness of the templates and that BERTSubs can dramatically outperform the baselines that use (literal-aware) knowledge graph embeddings, non-contextual word embeddings and the state-of-the-art OWL ontology embeddings.
2022
Results of the Ontology Alignment Evaluation Initiative 2022
OAEI Organisers
OM@ISWC 2022
TL;DR: A Joint report for results of different OAEI tracks in 2022.
Abstract:
Improving Language Model Predictions via Prompts Enriched with Knowledge Graphs
Ryan Brate, Minh-Hoang Dang, Fabian Hoppe, Yuan He, Albert Meroño Peñuela, Vijay Sadashivaiah
DL4KG@ISWC 2022
TL;DR: Workshop paper resulted from the collaboration in ISWS.
Abstract: Despite advances in deep learning and knowledge graphs (KGs), using language models for natural language understanding and question answering remains a challenging task. Pre-trained language models (PLMs) have shown to be able to leverage contextual information, to complete cloze prompts, next sentence completion and question answering tasks in various domains. Unlike structured data querying in e.g. KGs, mapping an input question to data that may or may not be stored by the language model is not a simple task. Recent studies have highlighted the improvements that can be made to the quality of information retrieved from PLMs by adding auxiliary data to otherwise naive prompts. In this paper, we explore the effects of enriching prompts with additional contextual information leveraged from the Wikidata KG on language model performance. Specifically, we compare the performance of naive vs. KG-engineered cloze prompts for entity genre classification in the movie domain. Selecting a broad range of commonly available Wikidata properties, we show that enrichment of cloze-style prompts with Wikidata information can result in a significantly higher recall for the investigated BERT and RoBERTa large PLMs. However, it is also apparent that the optimum level of data enrichment differs between models.

Machine Learning-Friendly Biomedical Datasets for Equivalence and Subsumption Ontology Matching
Yuan He, Jiaoyan Chen, Hang Dong, Ernesto Jiménez-Ruiz, Ali Hadian, Ian Horrocks
ISWC 2022 Best Resource Paper Candidate
TL;DR: Resource paper for the OAEI Bio-ML track.
Abstract: Ontology Matching (OM) plays an important role in many domains such as bioinformatics and the Semantic Web, and its research is becoming increasingly popular, especially with the application of machine learning (ML) techniques. Although the Ontology Alignment Evaluation Initiative (OAEI) represents an impressive effort for the systematic evaluation of OM systems, it still suffers from several limitations including limited evaluation of subsumption mappings, suboptimal reference mappings, and limited support for the evaluation of ML-based systems. To tackle these limitations, we introduce five new biomedical OM tasks involving ontologies extracted from Mondo and UMLS. Each task includes both equivalence and subsumption matching; the quality of reference mappings is ensured by human curation, ontology pruning, etc.; and a comprehensive evaluation framework is proposed to measure OM performance from various perspectives for both ML-based and non-ML-based OM systems. We report evaluation results for OM systems of different types to demonstrate the usage of these resources, all of which are publicly available as part of the new Bio-ML track at OAEI 2022.
[Preprint] [Paper] [Website] [Slides] [Poster] [Certificate]
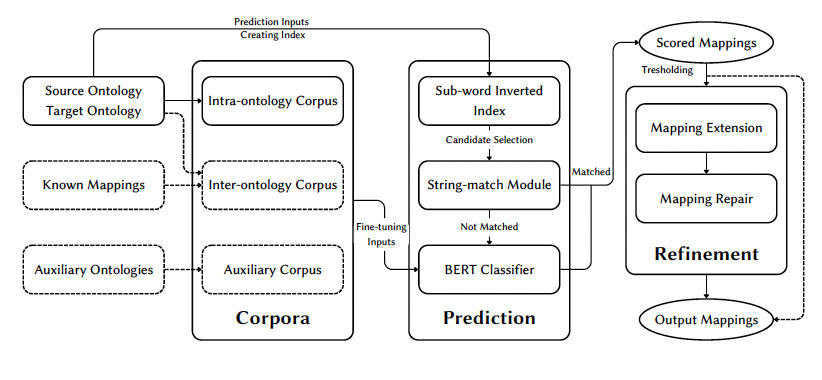
BERTMap: A BERT-based Ontology Alignment System
Yuan He, Jiaoyan Chen, Denvar Antonyrajah, Ian Horrocks
AAAI 2022
TL;DR: We introduce BERTMap, a pipeline ontology alignment system that leverages textual information from input ontologies to fine-tune BERT for lexical matching, structural and logical information to further refine the output mappings.
Abstract: Ontology alignment (a.k.a ontology matching (OM)) plays a critical role in knowledge integration. Owing to the success of machine learning in many domains, it has been applied in OM. However, the existing methods, which often adopt ad-hoc feature engineering or non-contextual word embeddings, have not yet outperformed rule-based systems especially in an unsupervised setting. In this paper, we propose a novel OM system named BERTMap which can support both unsupervised and semi-supervised settings. It first predicts mappings using a classifier based on fine-tuning the contextual embedding model BERT on text semantics corpora extracted from ontologies, and then refines the mappings through extension and repair by utilizing the ontology structure and logic. Our evaluation with three alignment tasks on biomedical ontologies demonstrates that BERTMap can often perform better than the leading OM systems LogMap and AML.
2021
2020
English-to-Chinese Transliteration with Phonetic Auxiliary Task
Yuan He, Shay Cohen
AACL 2020
TL;DR: Engligh-to-Chinese transliteration with dual tasks (En2Ch and En2Pinyin).
Abstract: Approaching named entities transliteration as a Neural Machine Translation (NMT) problem is common practice. While many have applied various NMT techniques to enhance machine transliteration models, few focus on the linguistic features particular to the relevant languages. In this paper, we investigate the effect of incorporating phonetic features for English-to-Chinese transliteration under the multi-task learning (MTL) setting—where we define a phonetic auxiliary task aimed to improve the generalization performance of the main transliteration task. In addition to our system, we also release a new English-to-Chinese dataset and propose a novel evaluation metric which considers multiple possible transliterations given a source name. Our results show that the multi-task model achieves similar performance as the previous state of the art with a model of a much smaller size.